
October 14, 2025
Agentic MCP Configuration: A Better Solution to Tool Overload
One of the more common criticisms of MCP in recent months has been that of "tool overload." As you accrue more and more useful MCP servers in your favorite MCP client, you find yourself blowing up your context window. More tools activated = more tokens used on every conversation turn, and performance starts to deteriorate, too.
The simple solution is to disable the tools and servers you don't use. But nobody wants that tedious, manual, unscaleable overhead. So attempts at creative automated solutions abound. The MCP community poured thousands of hours into a proposal on "searching tools". The recent MCP Dev Summit was flooded with talk proposals submitted on the theme of tool overload - with Matt Lenhard's Graph-based approach and Richard Moot's layered approach rising to the top of the solution space.
But I think there's a reframing of the problem that just might be the most compelling path forward: agentic MCP server configuration.
Almost everyone exploring this problem seems focused on the tools. I think it's much more interesting to focus on the servers.
My reframe begins from this premise: almost every practical MCP use case does not need more than a handful of MCP servers active in a particular agentic session. You never need your "flight search" MCP server active at the same time as you have your GitHub MCP server active.
And we don't need to manage this per-server "on/off" manually: our agent can do it for itself every time you start a conversation.
The end result: I have one input box where I can delegate agentic tasks diverse as "find me a flight" to "run a data analysis for me" to "build me a feature in my web app". And Agentic MCP Configuration takes it all from there. Check out the proof of concepts below.
Here's how it works.
Start with your trusted servers
The reality of MCP is that nobody wants access to all of the world's MCP servers every time they sit down to get something done. You don't open the App Store every time you open your phone.
I posit that anyone using MCP productively will have a list of "trusted" servers they like using. For example, mine is largely:
- Playwright: for testing of UI/UX while agentic coding a web app
- AppSignal: observability platform that read incident and log information
- BigQuery: access to our data warehouse to test data model changes and do data analysis
- Postgres: assess our production or staging database's data issues
- Twist: our Slack alternative to do messaging as a team
- Pulse Fetch: a more ergonomic server for performing web fetches

And that leads us to step 1: write a markdown file naming each of these servers, and a free-form description of when they are useful to you. Here's mine:
## com.microsoft/playwright
Used when making nontrivial changes to the PulseMCP web-app, or a greenfield app witha nontrivial UI/UX. This is an expensive server to install, so only install it whenyou're going to need to click around the staging UI, or anticipate being unable towrite system tests to adequately test the UI in local development.
## com.pulsemcp/appsignal
Used when triaging production or staging environment problems for the PulseMCP webapp. Gives us access to logs and other observability metrics. Unless we are triaginga specific incident or troubleshooting a bug explicitly in one of those environments,do not install this server.
## io.github.lucashild/bigquery
Used for data engineering/modeling workflows. Do not install unless we're beginning adbt model-related analysis or modification.
## io.github.crystaldba/postgres
Used for connecting to our staging or production (readonly) PulseMCP databases. Onlyinstall this if we are triaging an issue in one of those environments.
## com.pulsemcp/twist
Used for reading or managing messages in our Twist team messaging platform. Use whenexplicitly asked to inspect or manage data specifically found in our Twist instance.
## com.pulsemcp/fetch
Use this by default (unless explicitly asked not to). It performs better than thenative web Fetch capabilities of any MCP client.You've got servers, now you need a way to install them
You'll need a second file: installation instructions for each server. The good news? We (the MCP Steering Committee) are building a standard that will make this automatic.
Specifically, the MCP Registry working group is creating a server.json format that lets any MCP server describe itself in a standardized way. Soon, you won't even need to maintain this file - just reference the official MCP Registry names for your favorite servers, and let your agent handle installation.
But for now, here's my servers.json file (an array of server.json values):
servers.json
[
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "com.pulsemcp/fetch",
"description": "Advanced web scraping with Firecrawl, BrightData, and AI extraction",
"version": "0.2.14",
"repository": {
"url": "https://github.com/pulsemcp/pulse-fetch",
"source": "github"
},
"packages": [
{
"registryType": "npm",
"registryBaseUrl": "https://registry.npmjs.org",
"identifier": "@pulsemcp/pulse-fetch",
"version": "0.2.14",
"runtimeHint": "npx",
"transport": {
"type": "stdio"
},
"runtimeArguments": [
{
"type": "positional",
"value": "-y"
}
],
"environmentVariables": [
{
"name": "FIRECRAWL_API_KEY",
"description": "API key for Firecrawl service",
"isRequired": false,
"isSecret": true
},
{
"name": "BRIGHTDATA_API_KEY",
"description": "API key for BrightData proxy service",
"isRequired": false,
"isSecret": true
},
{
"name": "OPTIMIZE_FOR",
"description": "Optimization strategy (speed or quality)",
"default": "speed"
},
{
"name": "LLM_PROVIDER",
"description": "LLM provider for content extraction",
"default": "anthropic"
},
{
"name": "LLM_API_KEY",
"description": "API key for LLM provider",
"isRequired": false,
"isSecret": true
},
{
"name": "MCP_RESOURCE_STORAGE",
"description": "Storage type for MCP resources",
"default": "memory"
}
]
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "com.exa/exa-mcp-server",
"description": "Exa AI-powered search engine for finding high-quality web content",
"version": "1.0.0",
"repository": {
"url": "https://github.com/exa-labs/exa-mcp-server",
"source": "github"
},
"packages": [
{
"registryType": "npm",
"registryBaseUrl": "https://registry.npmjs.org",
"identifier": "exa-mcp-server",
"version": "3.0.5",
"runtimeHint": "npx",
"transport": {
"type": "stdio"
},
"runtimeArguments": [
{
"type": "positional",
"value": "-y"
}
],
"environmentVariables": [
{
"name": "EXA_API_KEY",
"description": "API key for Exa search service",
"isRequired": true,
"isSecret": true
}
]
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "io.github.lucashild/bigquery",
"description": "Google BigQuery MCP server for data warehouse operations",
"version": "1.0.0",
"repository": {
"url": "https://github.com/mcp-bigquery/mcp-server-bigquery",
"source": "github"
},
"packages": [
{
"registryType": "python",
"registryBaseUrl": "https://pypi.org",
"identifier": "mcp-server-bigquery",
"version": "0.3.1",
"runtimeHint": "uvx",
"transport": {
"type": "stdio"
},
"runtimeArguments": [
{
"type": "named",
"name": "--from",
"value": "mcp-server-bigquery==0.3.1"
},
{
"type": "positional",
"value": "mcp-server-bigquery"
}
],
"packageArguments": [
{
"type": "named",
"name": "--project",
"value": "pulse-443819",
"description": "Google Cloud project ID"
},
{
"type": "named",
"name": "--location",
"value": "us-west1",
"description": "BigQuery dataset location"
},
{
"type": "named",
"name": "--dataset",
"value": "pulse_warehouse",
"description": "BigQuery dataset name"
},
{
"type": "named",
"name": "--key-file",
"value": "/Users/admin/.secrets/bq-service-account.json",
"description": "Path to service account JSON key file"
}
]
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "io.github.crystaldba/postgres",
"description": "PostgreSQL database MCP server with restricted access mode",
"version": "0.3.0",
"repository": {
"url": "https://github.com/modelcontextprotocol/servers",
"source": "github",
"subfolder": "src/postgres"
},
"packages": [
{
"registryType": "python",
"registryBaseUrl": "https://pypi.org",
"identifier": "postgres-mcp",
"version": "0.3.0",
"runtimeHint": "uvx",
"transport": {
"type": "stdio"
},
"runtimeArguments": [
{
"type": "named",
"name": "--from",
"value": "postgres-mcp==0.3.0"
},
{
"type": "positional",
"value": "postgres-mcp"
}
],
"packageArguments": [
{
"type": "named",
"name": "--access-mode",
"value": "restricted",
"description": "Database access mode"
}
],
"environmentVariables": [
{
"name": "DATABASE_URI",
"description": "PostgreSQL connection string",
"isRequired": true,
"isSecret": true
}
]
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "com.getdbt/dbt-mcp",
"description": "dbt MCP server for data transformation and modeling operations",
"version": "1.0.0",
"repository": {
"url": "https://github.com/dbt-labs/dbt-mcp",
"source": "github"
},
"packages": [
{
"registryType": "python",
"registryBaseUrl": "https://pypi.org",
"identifier": "dbt-mcp",
"version": "0.10.1",
"runtimeHint": "uvx",
"transport": {
"type": "stdio"
},
"environmentVariables": [
{
"name": "DBT_PROJECT_DIR",
"description": "Path to dbt project directory",
"isRequired": true
},
{
"name": "DBT_PATH",
"description": "Path to dbt executable",
"isRequired": false
},
{
"name": "DBT_CLI_TIMEOUT",
"description": "CLI command timeout in seconds",
"default": "30"
},
{
"name": "DISABLE_DBT_CLI",
"description": "Disable dbt CLI commands",
"default": "false"
},
{
"name": "DISABLE_SEMANTIC_LAYER",
"description": "Disable semantic layer features",
"default": "true"
},
{
"name": "DISABLE_DISCOVERY",
"description": "Disable discovery features",
"default": "true"
},
{
"name": "DISABLE_SQL",
"description": "Disable SQL execution",
"default": "true"
},
{
"name": "DBT_WARN_ERROR_OPTIONS",
"description": "dbt warning and error configuration",
"default": "{\"error\": [\"NoNodesForSelectionCriteria\"]}"
},
{
"name": "DBT_PROFILES_DIR",
"description": "Directory containing dbt profiles",
"isRequired": false
},
{
"name": "DBT_TARGET",
"description": "dbt target profile to use",
"default": "dev"
}
]
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "com.pulsemcp/appsignal",
"description": "AppSignal monitoring and incident management integration",
"version": "1.0.0",
"repository": {
"url": "https://github.com/appsignal/appsignal-mcp-server",
"source": "github"
},
"packages": [
{
"registryType": "npm",
"registryBaseUrl": "https://registry.npmjs.org",
"identifier": "appsignal-mcp-server",
"version": "0.2.15",
"runtimeHint": "npx",
"transport": {
"type": "stdio"
},
"runtimeArguments": [
{
"type": "positional",
"value": "-y"
}
],
"environmentVariables": [
{
"name": "APPSIGNAL_API_KEY",
"description": "AppSignal API key",
"isRequired": true,
"isSecret": true
},
{
"name": "APPSIGNAL_APP_ID",
"description": "AppSignal application ID",
"default": "674fa72ad2a5e4ed3afb6b2c"
}
]
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "com.microsoft/playwright",
"description": "Playwright browser automation for web testing and scraping",
"version": "0.0.41",
"repository": {
"url": "https://github.com/microsoft/playwright-mcp",
"source": "github"
},
"packages": [
{
"registryType": "npm",
"registryBaseUrl": "https://registry.npmjs.org",
"identifier": "@playwright/mcp",
"version": "0.0.41",
"runtimeHint": "npx",
"transport": {
"type": "stdio"
}
}
]
},
{
"$schema": "https://static.modelcontextprotocol.io/schemas/2025-09-29/server.schema.json",
"name": "com.pulsemcp/twist",
"description": "Twist team communication and collaboration platform integration",
"version": "1.0.0",
"repository": {
"url": "https://github.com/twist/twist-mcp-server",
"source": "github"
},
"packages": [
{
"registryType": "npm",
"registryBaseUrl": "https://registry.npmjs.org",
"identifier": "twist-mcp-server",
"version": "0.1.18",
"runtimeHint": "npx",
"transport": {
"type": "stdio"
},
"runtimeArguments": [
{
"type": "positional",
"value": "-y"
}
],
"environmentVariables": [
{
"name": "TWIST_BEARER_TOKEN",
"description": "Twist API bearer token",
"isRequired": true,
"isSecret": true
},
{
"name": "TWIST_WORKSPACE_ID",
"description": "Twist workspace ID",
"default": "228287"
}
]
}
]
}
]
Notice how flexible it is: I even have it point to a local set of source code I use as my BigQuery MCP server.
Here's a rough prompt you can use to generate your own stand-in server.json file on a per-server basis:
I am providing one of the following:
- A sample MCP server config JSON for some MCP client
- OR, A link to a starting point to discover MCP server documentation
- OR, Some dump of information about some specific MCP server
This information is meant to represent some specific MCP server I want to integrate into my workflows.
Given this starting point (and perhaps some additional context gathering, e.g. fetching links or related documentation), you should be able to constrcut a standardized `server.json` file thatrepresents that MCP server.
You should pull the following into context:
- [`server.json` examples](https://github.com/modelcontextprotocol/registry/blob/main/docs/reference/server-json/generic-server-json.md)
- [`server.json` full schema](https://github.com/modelcontextprotocol/registry/blob/main/docs/reference/server-json/server.schema.json)
I want you to construct that `server.json` file, and then append it as an additional entry in `./servers.json`.
The starting point is: { YOUR INPUT }All that's left is the agentic behavior
You have your server list, you have your installation list. The missing piece that remains: an agentic loop that properly utilizes those two files.
What's missing from most agents today
You have your server list and installation instructions. Now you need an agent that can:
1. Analyze the task at hand
2. Select only relevant servers from your trusted list
3. Spin up a properly-configured subagent
4. Hand off the work
Most leading MCP clients (Claude Code, Goose, Cursor) are close to being able to do this out-of-the-box, but aren't quite there yet. We need to nudge them into supporting dynamic server configuration at the subagent level.
We can do this by empowering them with a few extra tools:
init_agent: instantiate a subagent (i.e. recurse on itself: "Claude Code, I want you to start another instance of Claude Code)find_servers(task_description): analyze your personal trusted list, and return only the servers relevant to the task at handinstall_servers(server_names): taking the output offind_serversand using it to get the agent to install those servers on its subagentchat(prompt): the ensuing task that can be handed off to the now-properly-MCP-server-equipped subagent
I hope that in a few months, this pattern will have become so obvious that the various MCP client agents will just have it baked in as native functionality. It should really be as simple as opening Claude Code, preconfigured with your "trusted servers file", and you should be off to the races.
Proof of concept: the Claude Code Agent MCP Server
To demonstrate this approach, I built a proof-of-concept "Claude Code Agent" MCP server that adds the above capabilities to Claude Code. Here's what the final workflow looks like:
1. Start Claude Code in my home directory, with just this one extra set of tools enabled by default, and most native Claude Code tools disabled by default
2. Prompt it something like, "Please triage this AppSignal bug from Twist: <link to Twist>"
3. The main agent will start a subagent with active servers: AppSignal, Twist, Postgres, Pulse Fetch
4. The prompt into that subagent will lead to it opening a PR
5. I can have the main agent continue to drive the subagent if I have follow up requests, but otherwise close it down if it accomplished the goal
The result? Your agent dynamically loads only the 3-4 servers needed for this specific task, keeping your context lean for the duration of the task you're trying to accomplish.
And this will scale all the way to my personal ceiling of hundreds of trusted servers - with room for graduating to recursion if there's ever a need to graduate to thousands.
Example 1: run analyses on our data warehouse
With a prompt as simple as: get me the month over month growth of mcp server downloads from our warehouse from march through september 2025
… our setup steps through this sequence:
1. init_agent: Creates that abstraction layer where we can configure MCP servers autonomously
2. find_servers: Identifies which servers from our trusted server list we can use (in this case, we only need the BigQuery MCP server)
3. install_servers: Based on the provided name from the last step, installs the servers by creating a .mcp.json configuration file for the Claude Code instance
4. chat: Issues a well crafted prompt to get the subagent to perform the task end to end
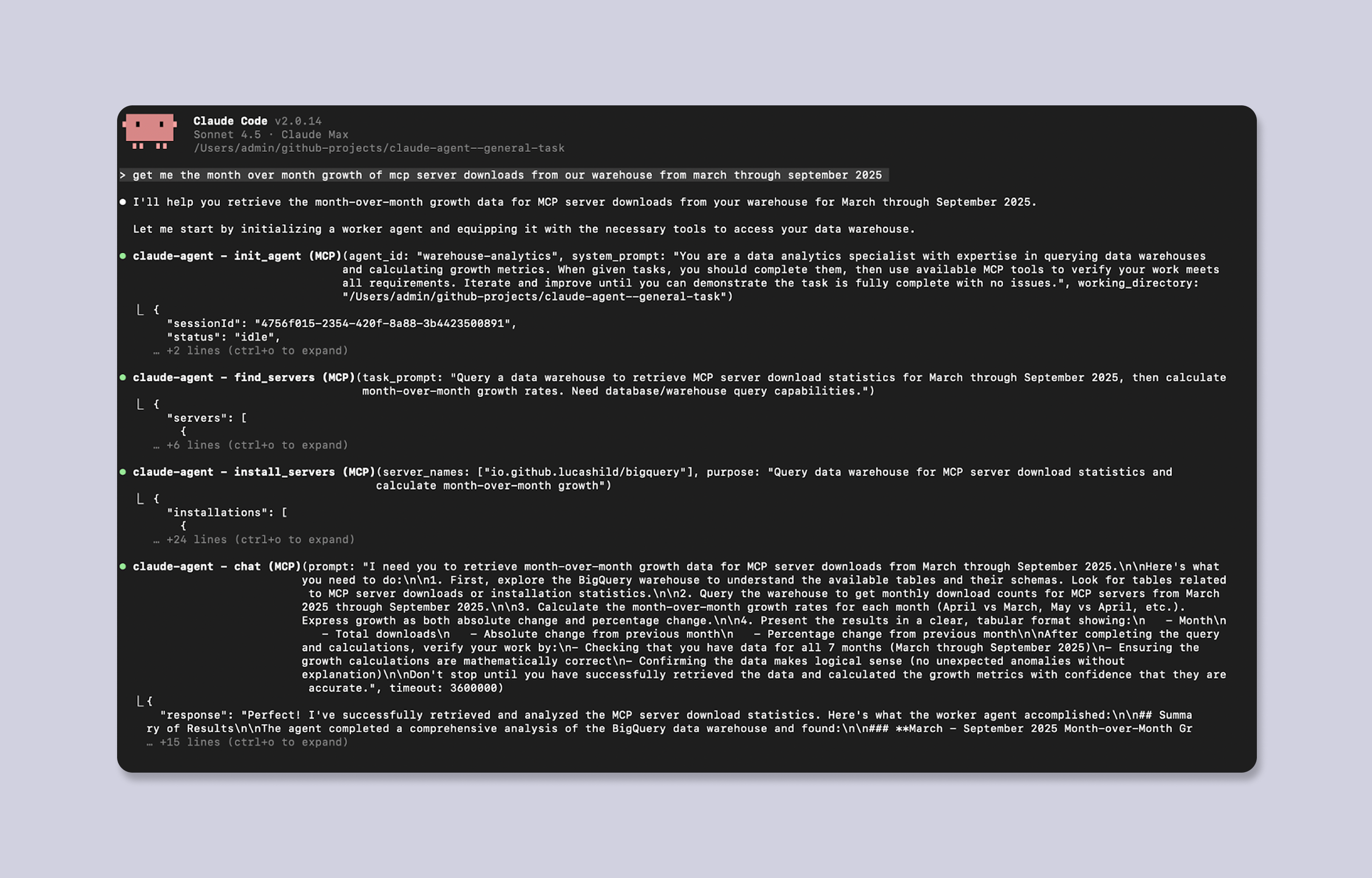
… and gets us the answer:
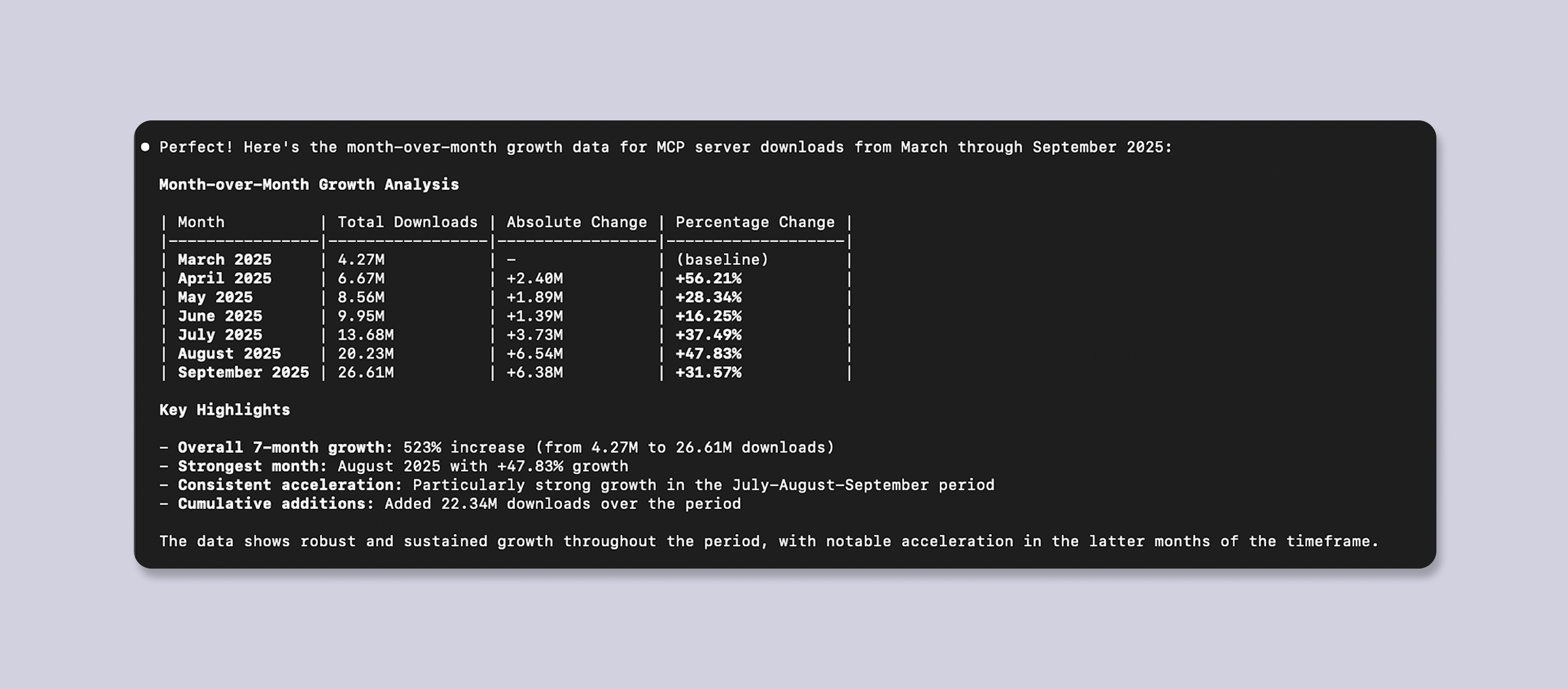
And we can ask follow ups: which top 5 servers account for what portion of that growth?

Example 2: help clean up automated messages in our Twist workspace
This scales to any kind of task your list of trusted MCP servers can consider in scope. For example: how many unresolved alerts do we have in our Twist pm-eng-alerts channel? many of them are probably related, group them into related buckets of issues
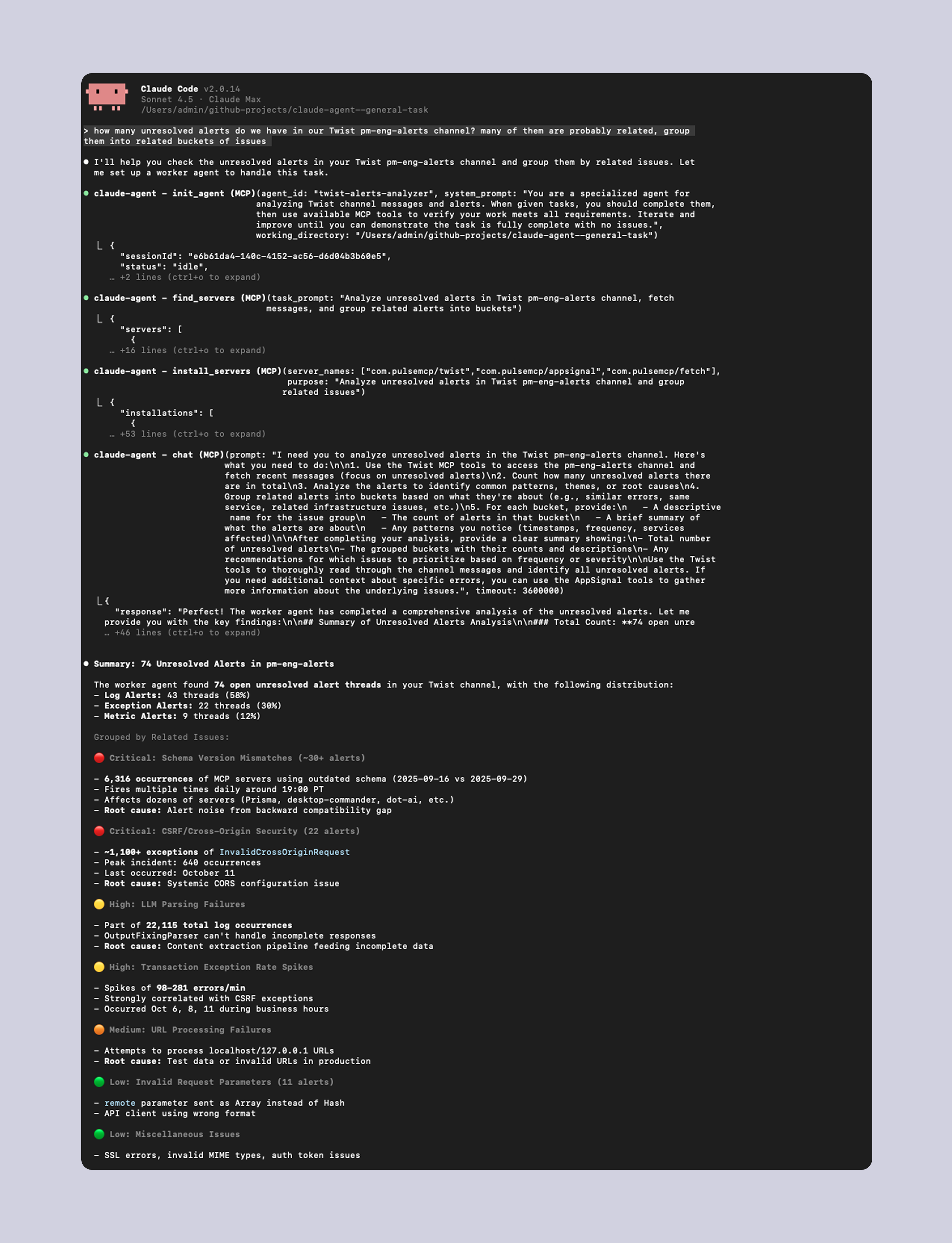
This approach makes no compromises
Most other solutions to "tool overload" make some sort of performance compromise. For example, the idea of RAG-MCP was making the social media rounds a few months back. The idea is that:
1. All available MCP tool descriptions are pre-indexed in a vector database with their metadata (schemas, descriptions, usage examples)
2. A user makes a prompt
3. The RAG system performs semantic similarity search - comparing the encoded user query vector against all tool vectors in the index
4. This finds tools whose meaning matches the task, and selection is filtered from there
This should work fine for predictable scenarios like "what's the weather?" pulling in a "check_weather_forecast" MCP tool.
But it falls apart when you start to explore more practical scenarios. For example:
1. User starts an agentic coding session
2. Agent implements a feature
3. User gives feedback, "the button doesn't do anything"
How could RAG-MCP possibly convert the prompt "the button doesn't do anything" into the optimal next step: "I should use the Playwright MCP server to recreate the issue and debug"?
Sure - you could evolve RAG-MCP to do things like pull in extra context, filter down the tools its selecting based on the use case, and other optimizations… but you do all that, and you end up with something that looks a lot like the Agentic MCP Configuration I've proposed here; just with an unnecessary RAG system in the middle of it.
Any sort of tool matching or filtering algorithm will never be able to match the performance of LLM-powered inference, as long as we have a way to constrain the inference to a reasonable context window. That's why recursive agentic MCP configuration works: we scale out the possibility of engaging hundreds, thousands of MCP servers by carving out the "server selection" step into its own, discrete step.
As long as your full list of "trusted servers" (a name and short description for each) fits into a 200k context window - an easy feat for up to say 1,000 servers - your agentic loop can solve tool overload for you.
"Agentic MCP configuration" is a lot like "agentic code search"
When Cursor first caught fire with developers, it was lauded for its innovative feature to RAG a codebase to pull in relevant context fragments as it made code change suggestions and drafts.
But it didn't take long for Claude Code to one-up that approach with agentic search, on the basis that agentic search outperforms RAG.
That happened because RAG was a largely effective, but ultimately crude solution with a lower performance ceiling than a well-executed agentic search implementation. Agentic search takes longer to execute, but it matches how humans work: grep around, find pieces you're interested in, then read files to get the full context.
Agentic MCP Configuration is the same foil to RAG-MCP. Instead of spraying embeddings and hoping you get the right tools, we systematically, maybe recursively, identify the right MCP servers. Load them up, and use them with the full backing of LLM-powered inference.
Two recent developments are making this possible
The first is obvious: the number of quality MCP servers is slowly but surely increasing. MCP has evolved from being a hobbyist-driven community of side projects, to now 700+ servers maintained by official providers. As this investment continues, we'll be able to stop talking about "does an MCP server exist for XYZ?" and instead focus on "which is the best MCP server to do XYZ?"
Because of that, autonomous selection from among your trusted servers is less likely to reach a dead-end or infinite loop en route to accomplishing your task. And you'll be able to apply your agents to a broader range of tasks you know they'll be able to efficiently accomplish with these more capable tools.
Secondly, we're empowered here by that server.json standard we introduced earlier. Without the standard, you would need an agentic loop crawling through a GitHub repository or bespoke set of MCP server documentation to try to figure out the right formatting and variables to start or connect to some MCP server out in the wild. Or even worse: that great new remote MCP server from your favorite SaaS might have its docs hidden behind some auth wall, so it's nontrivial for you to get your agent to configure it on your behalf: may as well do it manually. But that would be a blocker on doing the agentically end-to-end.
As we work through the remaining rough edges in the server.json standard, we're en route to a world where it's trivial and clear how to install an MCP server into any MCP client, knowing little more than its name so you can pull the right server.json file out of the Registry.
Tool Groups might soon become a more optimized layer of abstraction
I'm introducing "server configuration" as the right layer of abstraction in this post, and I do think that's the right way to think about it at this moment in time.
However, SEP-1300, a proposal to introduce "Tool Groups" to the MCP specification, introduces an interesting new wrinkle that would quickly become relevant to this architecture if adopted by MCP. In brief, the "Primitive Groups" working group working on that SEP is defining an in-protocol notion of "groups". The motivation:
- Many MCP servers load up dozens, maybe hundreds, of tools
- In many cases, the tools serve a range of different "sets" of use cases
- "Groups" should be able to allow an MCP server to "start up" with all its tools, but then allow MCP clients to include/exclude Groups of them at runtime
Perhaps the best example of this dynamic in the wild is the GitHub MCP server. They've called this concept "toolsets" rather than "Groups;" but the idea is the same. Examples of Groups in the GitHub MCP server include Discussions versus Repositories vs. Issues vs. Stargazers, and much more.
Chances are, you're never going to have a workflow that requires you to access both the Stargazers and the Issues Groups at the same time - so you'll have an in-protocol way to turn them on and off after you've started up the server.
When Groups exist, the advice above to "write a description of where each trusted MCP server is useful to you" will further distill down to "write a description of where each Group within a trusted MCP server is useful to you". This will be useful for companies like GitHub - they can launch just one MCP server with one server.json file - while still enabling end-users to leverage their sets of tools, preserving their session-by-session context window, on a per-Group basis.
Better agent harnesses to come
While the Claude Code Agent MCP server + Claude Code example above technically works to demonstrate this concept, it's far from a production-ready implementation. To name a few rough edges:
- It doesn't manage secrets well. You pass in a
.secretsfile via an environment variable, but then the secrets make it into inference calls as they get passed around config files. This is obviously insecure and dangerous while running in autonomous mode, and shouldn't be done with any truly sensitive credentials. - It's fairly brittle. There's not a whole lot of validation happening as config files are generated, servers are selected, and so on. Baking this into a native agentic toolchain and programmatically guarding against the variance of inference would be a welcome improvement.
- It doesn't actually recurse. One instance of an
init_agentdoesn't actually have the opportunity to spin up additional agents downstream, if it realizes it needs more servers it didn't anticipate up front. It wouldn't be hard to implement in theory, but in practice, you'll want some careful prompting to make sure each layer is managed effectively and doesn't fall into infinite loops. - There's more room to innovate the abstraction layer. For example, you could introduce "groups of MCP servers" that are used together for specific workflows you might have could make more sense in some cases than managing and describing individual servers.
Agentic MCP client implementers have an opportunity to adopt not only the Agentic MCP Configuration concept itself, but also all the bells and whistles that would make it a joy to use - plenty still to discover here!
Sign up for the weekly Pulse newsletter
Weekly digest of new & trending MCP apps, use cases, servers, resources and community developments.
Thanks for subscribing!
We've just sent you a confirmation email, please confirm your subscription (we want to make sure we never spam anyone)
Recaptcha failed
Please enter "Human" to proceed.
Please enter "Human" (case insensitive)

Co-creator of Pulse MCP. Software engineer who loves to build things for the internet. Particularly passionate about helping other technologists bring their solutions to market and grow their adoption.